
A Very Big Video Reasoning Suite
Maijunxian Wang*, Ruisi Wang*, Juyi Lin*, Ran Ji*, Thaddäus Wiedemer, Qingying Gao,
Dezhi Luo, Yaoyao Qian, Lianyu Huang, Zelong Hong, Jiahui Ge, Qianli Ma, Hang He,
Yifan Zhou, Lingzi Guo, Lantao Mei, Jiachen Li, Hanwen Xing, Tianqi Zhao, Fengyuan Yu,
Weihang Xiao, Yizheng Jiao, Jianheng Hou, Danyang Zhang, Pengcheng Xu, Boyang Zhong,
Zehong Zhao, Gaoyun Fang, John Kitaoka, Yile Xu, Hua Xu, Kenton Blacutt, Tin Nguyen,
Siyuan Song, Haoran Sun, Shaoyue Wen, Linyang He, Runming Wang, Yanzhi Wang,
Mengyue Yang, Ziqiao Ma, Raphaël Millière, Freda Shi, Nuno Vasconcelos,
Daniel Khashabi, Alan Yuille, Yilun Du, Ziming Liu, Bo Li, Dahua Lin, Ziwei Liu,
Vikash Kumar, Yijiang Li, Lei Yang, Zhongang Cai✉, Hokin Deng✉.
International Conference on Machine Learning (ICML), 2026
(Hugging Face #1 Paper of the Month, February 2026)
Homepage
PDF
Data
Model
EvalKit
Leaderboard
Demystifying Video Reasoning
Ruisi Wang, Zhongang Cai✉, Fanyi Pu, Junxiang Xu, Wanqi Yin, Maijunxian Wang, Ran Ji, Chenyang Gu, Bo Li, Ziqi Huang, Hokin Deng, Dahua Lin, Ziwei Liu, Lei Yang.
European Conference on Computer Vision (ECCV), 2026
(Hugging Face #1 Paper of the Day, 18 March 2026)
Homepage
PDF
Video
Code
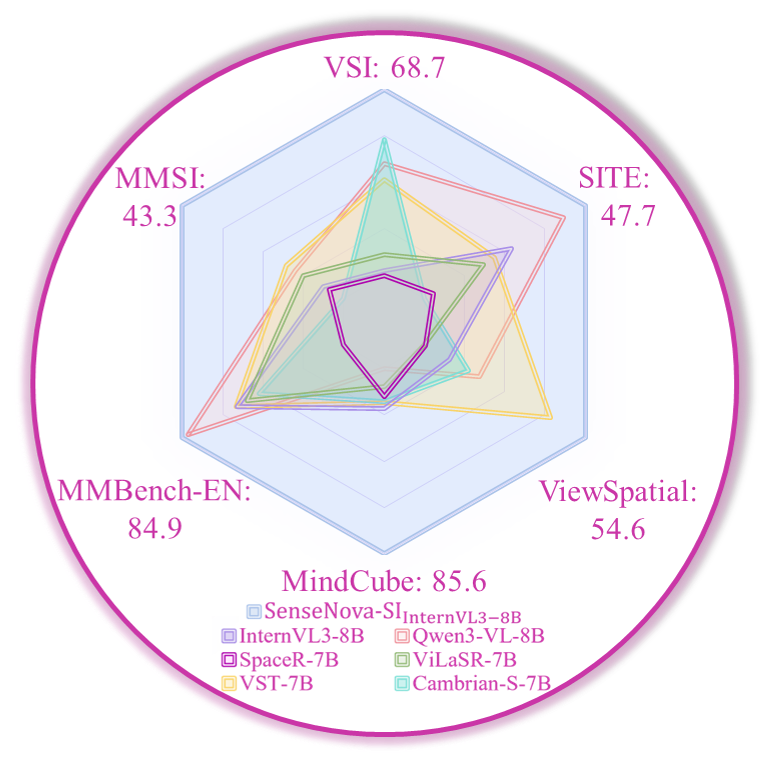
Scaling Spatial Intelligence with Multimodal Foundation Models
Zhongang Cai*, Ruisi Wang*, Chenyang Gu*, Fanyi Pu*, Junxiang Xu*, Yubo Wang*, Wanqi Yin*, Zhitao Yang*, Chen Wei*, Qingping Sun*,
Tongxi Zhou*, Jiaqi Li*, Hui En Pang*, Oscar Qian*, Yukun Wei, Zhiqian Lin, Xuanke Shi, Kewang Deng, Xiaoyang Han, Zukai Chen,
Xiangyu Fan, Hanming Deng, Lewei Lu, Liang Pan, Bo Li, Ziwei Liu✉, Quan Wang✉, Dahua Lin✉, Lei Yang*✉.
Computer Vision and Pattern Recognition (CVPR), 2026
PDF
Code
HuggingFace
ModelScope
